
Linux 性能优化实战
开篇
如何学习Linux性能优化?
理解组件之间的工作原理和协作方式
性能指标是什么?

性能分析,其实就是找出应用或系统的瓶颈,并设法去避免或者缓解它们
步骤:
- 选择指标评估应用程序和系统的性能;
- 为应用程序和系统设置性能目标;
- 进行性能基准测试;
- 性能分析定位瓶颈;
- 优化系统和应用程序;
- 性能监控和告警。
布伦丹·格雷格(Brendan Gregg)
https://www.brendangregg.com/ 性能领域的大师,DTrace作者
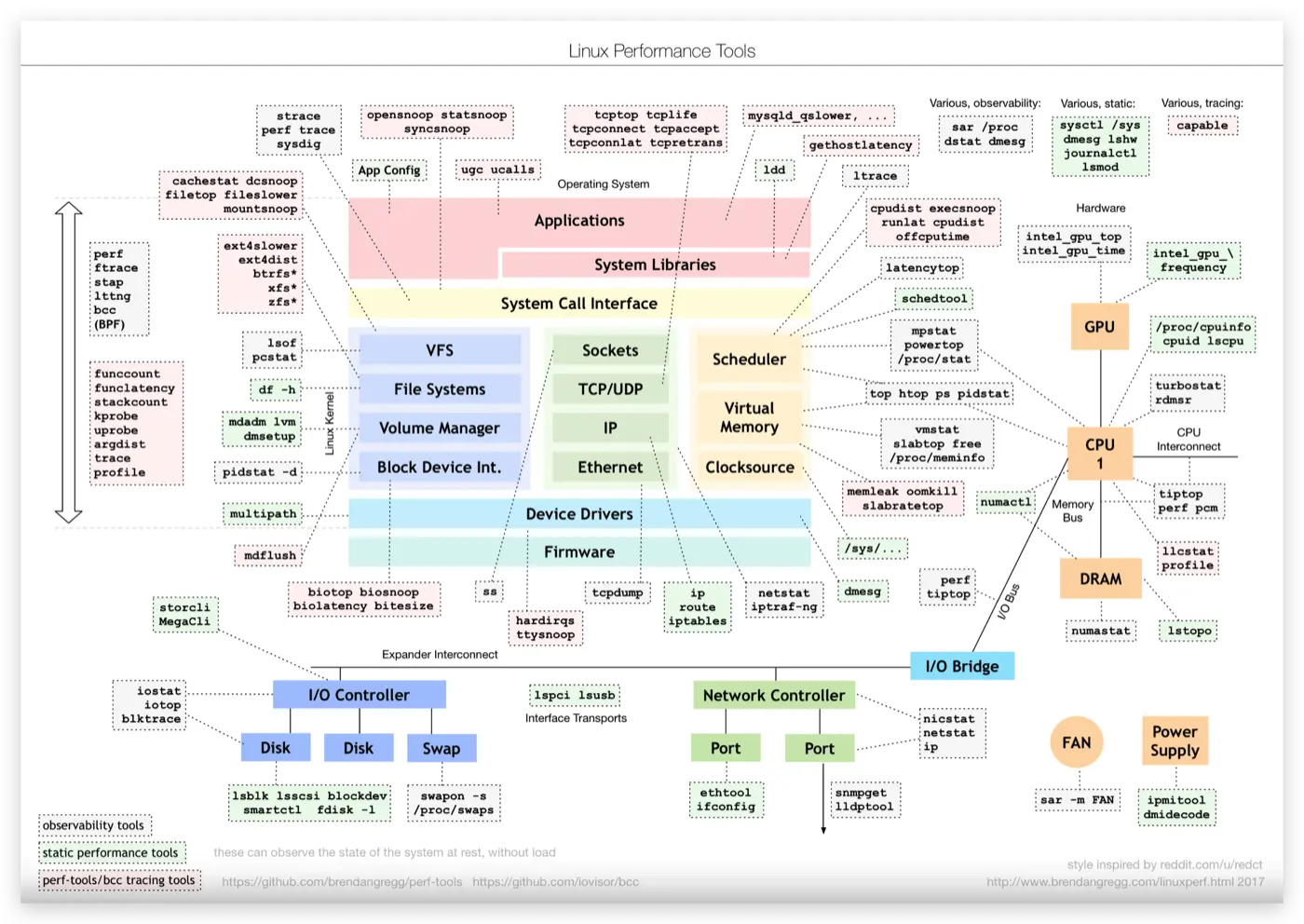
Linux 性能工具图谱:
怎么学更高效?
- 虽然系统的原理很重要,但在刚开始一定不要试图抓住所有的实现细节
- 有哪些指标可以衡量性能?
- 使用什么样的性能工具来观察指标?
- 导致这些指标变化的因素等。
- 边学边实践,通过大量的案例演习掌握 Linux 性能的分析和优化
- 勤思考,多反思,善总结,多问为什么
CPU性能篇
基础篇:到底应该怎么理解“平均负载”?
$ uptime
15:50:30 up 10 days, 23:03, 2 users, load average: 0.00, 0.00, 0.00
#
# 15:50:30 当前时间
# up 10 days, 23:03, 系统运行时间
# 2 users, 正在登录用户数
# load average: 0.07, 0.05, 0.01 过去 1 分钟、5 分钟、15 分钟的平均负载(Load Average)平均负载
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系
可运行状态:是指正在使用 CPU 或者正在等待 CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态(Running 或 Runnable)的进程
不可中断状态的进程:是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的 I/O 响应,也就是我们在 ps 命令中看到的 D 状态(Uninterruptible Sleep,也称为 Disk Sleep)的进程
当数值为2时,代表:
- 在只有 2 个 CPU 的系统上,意味着所有的 CPU 都刚好被完全占用。
- 在 4 个 CPU 的系统上,意味着 CPU 有 50% 的空闲。
- 而在只有 1 个 CPU 的系统中,则意味着有一半的进程竞争不到 CPU。
平均负载为多少时合理
平均负载最理想的情况是等于 CPU 个数
查看cpu个数:
$ grep 'model name' /proc/cpuinfo | wc -l三个不同时间间隔的平均值,分析系统负载趋势的数据来源,让我们能更全面、更立体地理解目前的负载状况。
在实际生产环境中,平均负载多高时,需要我们重点关注呢?
在作者看来,当平均负载高于 CPU 数量 70% 的时候,你就应该分析排查负载高的问题了。并不是绝对的
平均负载与 CPU 使用率
CPU 使用率:是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应
- CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;
- I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;
- 大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高
平均负载案例分析
机器配置:2 CPU,8GB 内存。
# 工具
$ sudo apt install stress sysstatstress:是一个 Linux 系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景
sysstat:包含了常用的 Linux 性能工具,用来监控和分析系统的性能。我们的案例会用到这个包的两个命令 mpstat 和 pidstat。
- mpstat: 是一个常用的多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有 CPU 的平均指标。
- pidstat: 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标。
场景一:CPU 密集型进程
$ stress --cpu 1 --timeout 600
# -d 参数表示高亮显示变化的区域
$ watch -d uptime
..., load average: 1.00, 0.75, 0.39
# -P ALL 表示监控所有CPU,后面数字5表示间隔5秒后输出一组数据
$ mpstat -P ALL 5
Linux 4.15.0 (ubuntu) 09/22/18 _x86_64_ (2 CPU)
13:30:06 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
13:30:11 all 50.05 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 49.95
13:30:11 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
13:30:11 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
# 间隔5秒后输出一组数据
$ pidstat -u 5 1
13:37:07 UID PID %usr %system %guest %wait %CPU CPU Command
13:37:12 0 2962 100.00 0.00 0.00 0.00 100.00 1 stressuptime:1 分钟的平均负载会慢慢增加到 1.00,mpstat:正好有一个 CPU 的使用率为 100%,但它的 iowait 只有 0。这说明,平均负载的升高正是由于 CPU 使用率为 100% 。
场景二:I/O 密集型进程
$ stress -i 1 --timeout 600
$ watch -d uptime
..., load average: 1.06, 0.58, 0.37
# 显示所有CPU的指标,并在间隔5秒输出一组数据
$ mpstat -P ALL 5 1
Linux 4.15.0 (ubuntu) 09/22/18 _x86_64_ (2 CPU)
13:41:28 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
13:41:33 all 0.21 0.00 12.07 32.67 0.00 0.21 0.00 0.00 0.00 54.84
13:41:33 0 0.43 0.00 23.87 67.53 0.00 0.43 0.00 0.00 0.00 7.74
13:41:33 1 0.00 0.00 0.81 0.20 0.00 0.00 0.00 0.00 0.00 98.99
# 间隔5秒后输出一组数据,-u表示CPU指标
$ pidstat -u 5 1
Linux 4.15.0 (ubuntu) 09/22/18 _x86_64_ (2 CPU)
13:42:08 UID PID %usr %system %guest %wait %CPU CPU Command
13:42:13 0 104 0.00 3.39 0.00 0.00 3.39 1 kworker/1:1H
13:42:13 0 109 0.00 0.40 0.00 0.00 0.40 0 kworker/0:1H
13:42:13 0 2997 2.00 35.53 0.00 3.99 37.52 1 stress
13:42:13 0 3057 0.00 0.40 0.00 0.00 0.40 0 pidstatuptime:1 分钟的平均负载会慢慢增加到 1.06,其中一个 CPU 的系统 CPU 使用率升高到了 23.87,而 iowait 高达 67.53%。这说明,平均负载的升高是由于 iowait 的升高。
场景三:大量进程的场景
$ stress -c 8 --timeout 600
$ uptime
..., load average: 7.97, 5.93, 3.02
# 间隔5秒后输出一组数据
$ pidstat -u 5 1
14:23:25 UID PID %usr %system %guest %wait %CPU CPU Command
14:23:30 0 3190 25.00 0.00 0.00 74.80 25.00 0 stress
14:23:30 0 3191 25.00 0.00 0.00 75.20 25.00 0 stress
14:23:30 0 3192 25.00 0.00 0.00 74.80 25.00 1 stress
14:23:30 0 3193 25.00 0.00 0.00 75.00 25.00 1 stress
14:23:30 0 3194 24.80 0.00 0.00 74.60 24.80 0 stress
14:23:30 0 3195 24.80 0.00 0.00 75.00 24.80 0 stress
14:23:30 0 3196 24.80 0.00 0.00 74.60 24.80 1 stress
14:23:30 0 3197 24.80 0.00 0.00 74.80 24.80 1 stress
14:23:30 0 3200 0.00 0.20 0.00 0.20 0.20 0 pidstat8 个进程在争抢 2 个 CPU,每个进程等待 CPU 的时间(也就是代码块中的 %wait 列)高达 75%。这些超出 CPU 计算能力的进程,最终导致 CPU 过载。
基础篇:经常说的 CPU 上下文切换是什么意思?
根据任务的不同,CPU 的上下文切换就可以分为几个不同的场景,也就是进程上下文切换、线程上下文切换以及中断上下文切换。
进程上下文切换
- 内核空间(Ring 0)具有最高权限,可以直接访问所有资源;
- 用户空间(Ring 3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源。
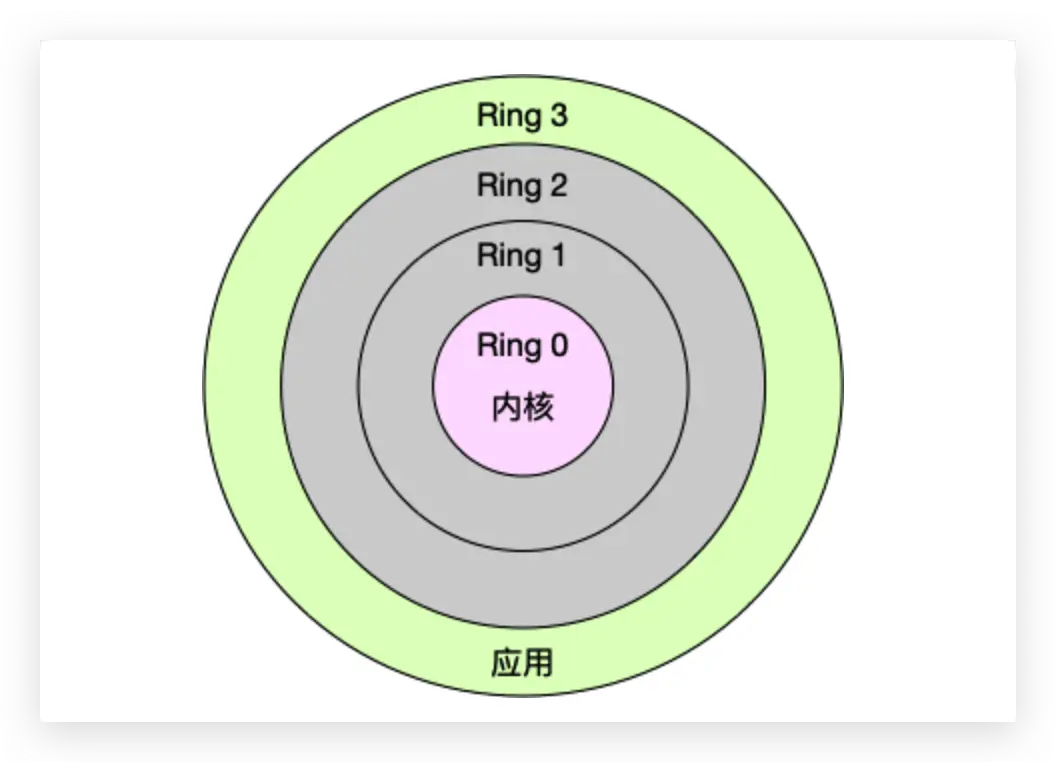
从用户态到内核态的转变,需要通过系统调用来完成
那么,系统调用的过程有没有发生 CPU 上下文的切换呢?答案自然是肯定的。CPU 寄存器里原来用户态的指令位置,需要先保存起来。接着,为了执行内核态代码,CPU 寄存器需要更新为内核态指令的新位置。最后才是跳转到内核态运行内核任务。
而系统调用结束后,CPU 寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程。所以,一次系统调用的过程,其实是发生了两次 CPU 上下文切换。
- 进程上下文切换,是指从一个进程切换到另一个进程运行。
- 而系统调用过程中一直是同一个进程在运行。
系统调用过程通常称为特权模式切换,而不是上下文切换。
- 其一,为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行。
- 其二,进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
- 其三,当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。
- 其四,当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
线程上下文切换
线程与进程最大的区别在于,线程是调度的基本单位,而进程则是资源拥有的基本单位。
- 当进程只有一个线程时,可以认为进程就等于线程。
- 当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
- 另外,线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
这么一来,线程的上下文切换其实就可以分为两种情况:
- 第一种, 前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样。
- 第二种,前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。
proc 文件系统。它是一种内核空间和用户空间进行通信的机制,可以用来查看内核的数据结构,或者用来动态修改内核的配置
套路篇:如何迅速分析出系统CPU的瓶颈在哪里?
CPU 性能指标
- CPU 使用率
- 用户 CPU 使用率,包括用户态 CPU 使用率(user)和低优先级用户态 CPU 使用率(nice),表示 CPU 在用户态运行的时间百分比。用户 CPU 使用率高,通常说明有应用程序比较繁忙。
- 系统 CPU 使用率,表示 CPU 在内核态运行的时间百分比(不包括中断)。系统 CPU 使用率高,说明内核比较繁忙。
- 等待 I/O 的 CPU 使用率,通常也称为 iowait,表示等待 I/O 的时间百分比。iowait 高,通常说明系统与硬件设备的 I/O 交互时间比较长。
- 软中断和硬中断的 CPU 使用率,分别表示内核调用软中断处理程序、硬中断处理程序的时间百分比。它们的使用率高,通常说明系统发生了大量的中断。
- 除了上面这些,还有在虚拟化环境中会用到的窃取 CPU 使用率(steal)和客户 CPU 使用率(guest),分别表示被其他虚拟机占用的 CPU 时间百分比,和运行客户虚拟机的 CPU 时间百分比。
- 应该是平均负载(Load Average),也就是系统的平均活跃进程数
- 进程上下文切换
- 无法获取资源而导致的自愿上下文切换;
- 被系统强制调度导致的非自愿上下文切换。
- CPU 缓存的命中率
性能工具
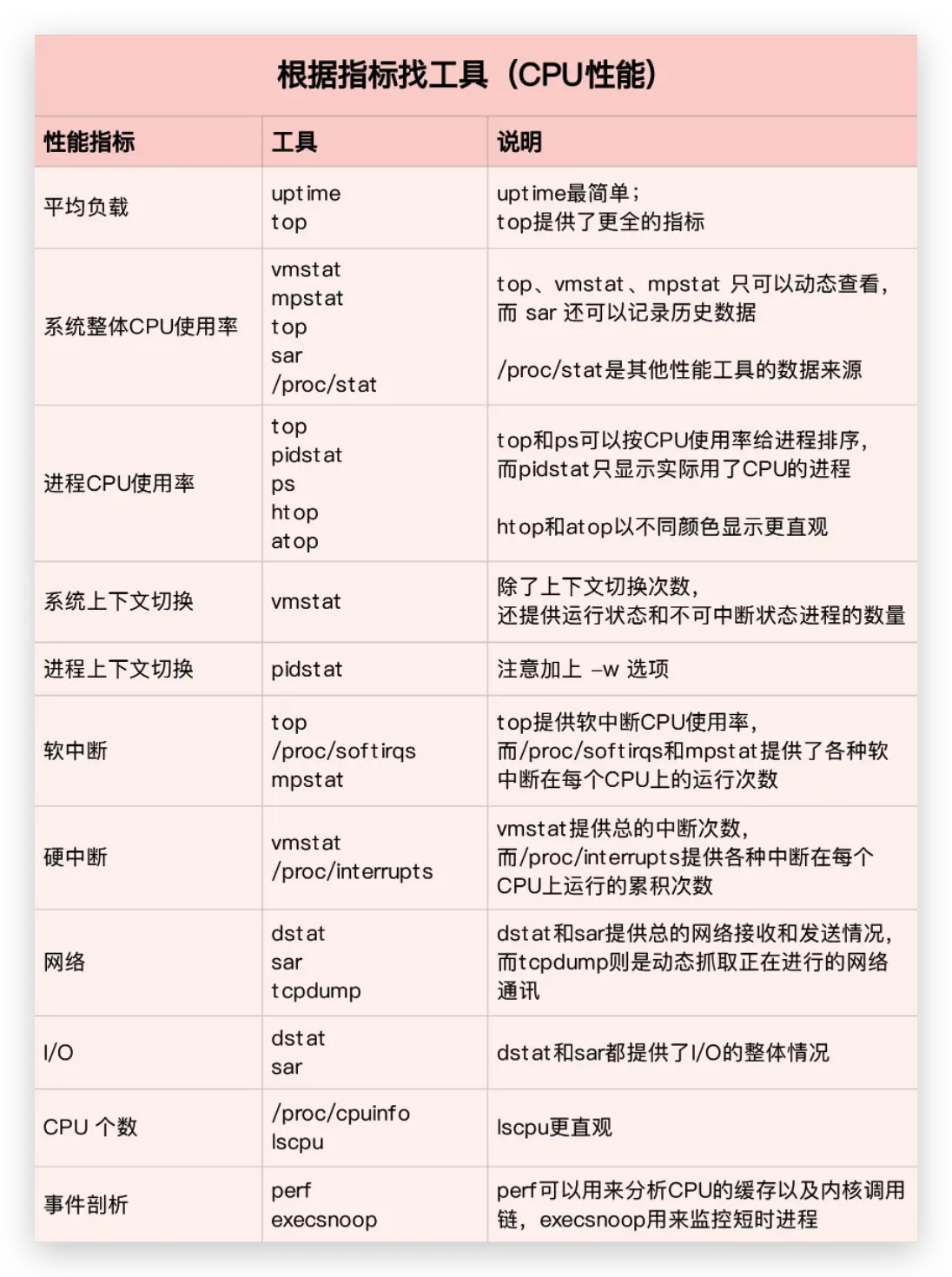
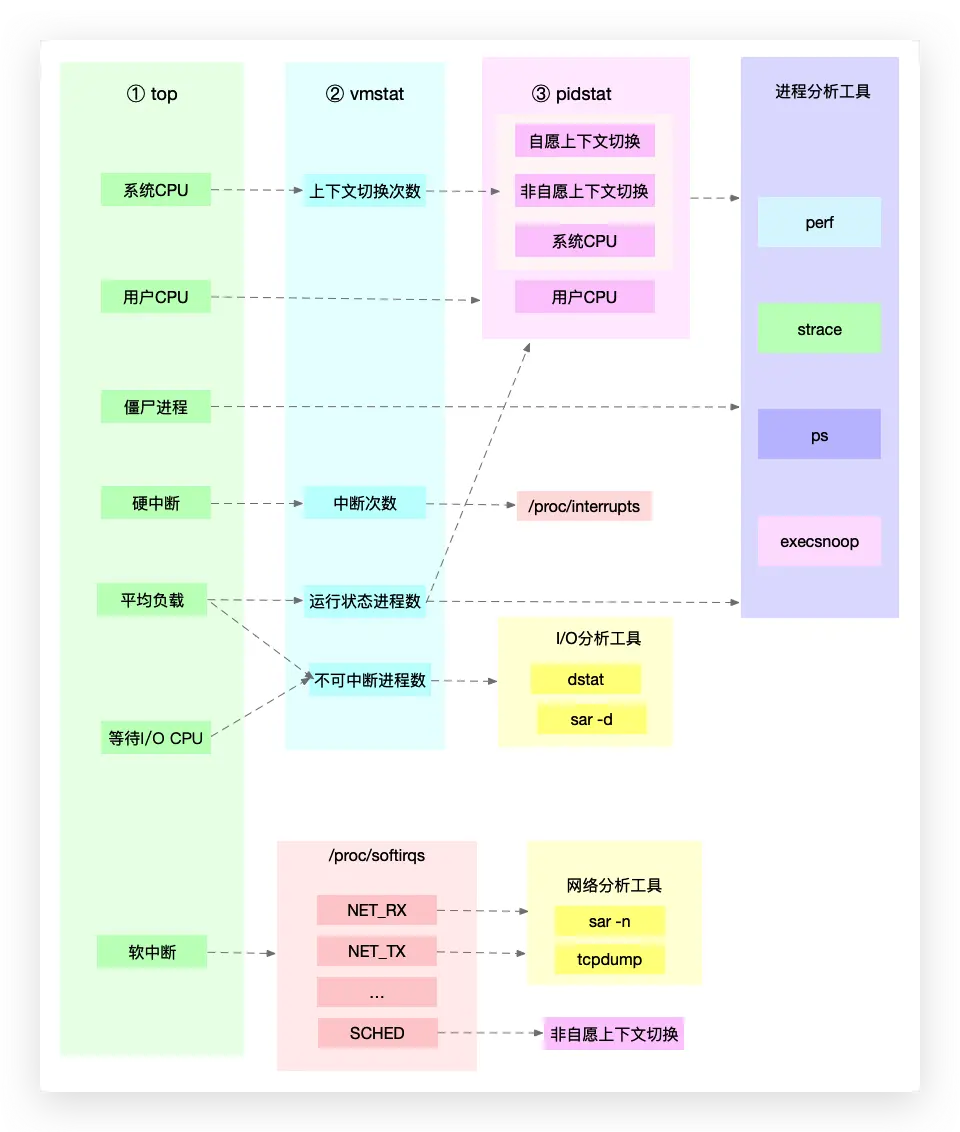
第一个维度,从 CPU 的性能指标出发。也就是说,当你要查看某个性能指标时,要清楚知道哪些工具可以做到。
第二个维度,从工具出发。也就是当你已经安装了某个工具后,要知道这个工具能提供哪些指标。
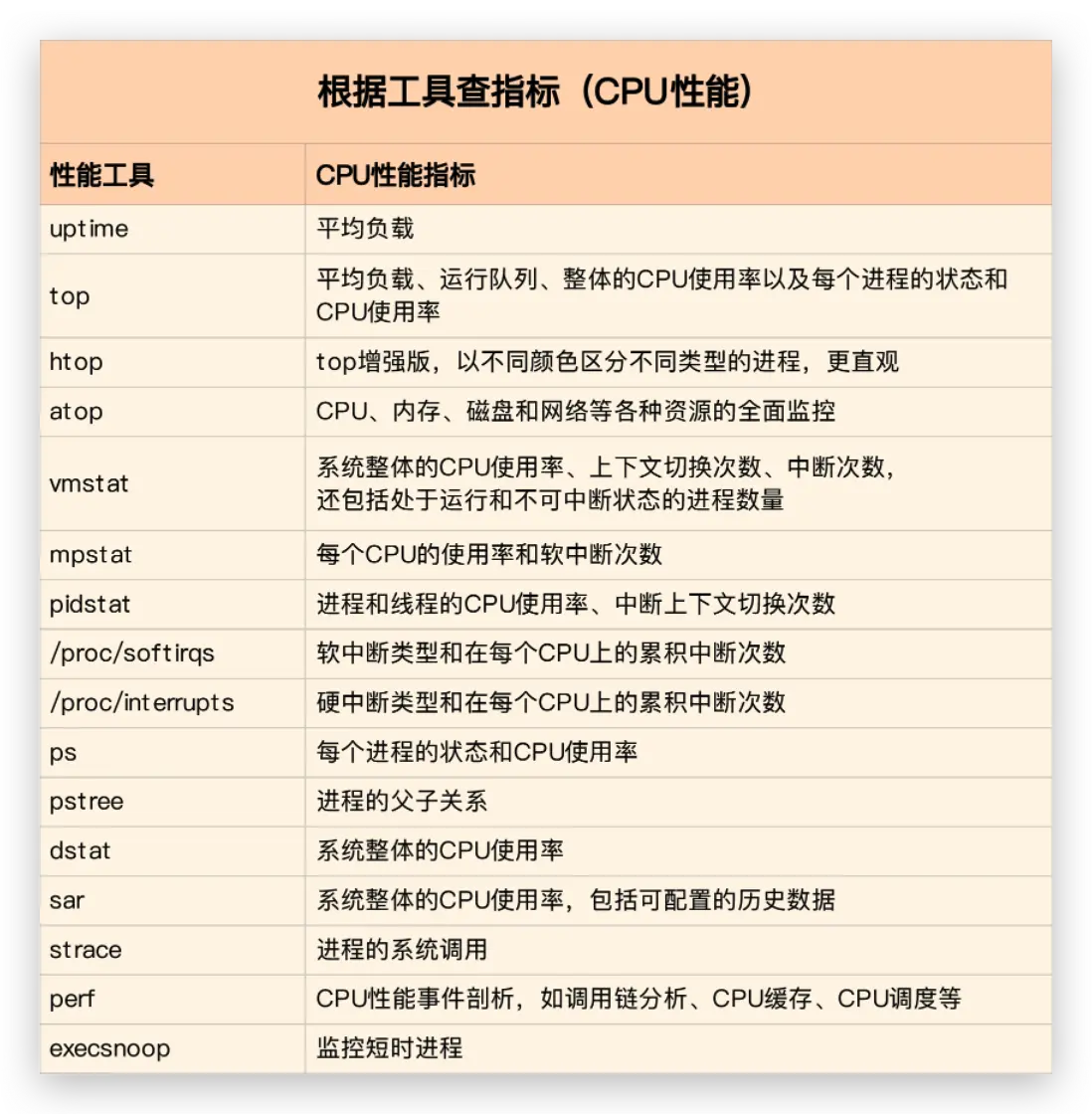
如何迅速分析 CPU 的性能瓶颈
想弄清楚性能指标的关联性,就要通晓每种性能指标的工作原理
举个例子,用户 CPU 使用率高,我们应该去排查进程的用户态而不是内核态。因为用户 CPU 使用率反映的就是用户态的 CPU 使用情况,而内核态的 CPU 使用情况只会反映到系统 CPU 使用率上。
为了缩小排查范围,我通常会先运行几个支持指标较多的工具,如 top、vmstat 和 pidstat
性能优化方法论
- 首先,既然要做性能优化,那要怎么判断它是不是有效呢?特别是优化后,到底能提升多少性能呢?
- 第二,性能问题通常不是独立的,如果有多个性能问题同时发生,你应该先优化哪一个呢?
- 第三,提升性能的方法并不是唯一的,当有多种方法可以选择时,你会选用哪一种呢?是不是总选那个最大程度提升性能的方法就行了呢?
怎么评估性能优化的效果?
- 确定性能的量化指标。
- 测试优化前的性能指标。
- 测试优化后的性能指标。
我的建议是不要局限在单一维度的指标上,你至少要从应用程序和系统资源这两个维度,分别选择不同的指标。比如,以 Web 应用为例:
- 应用程序的维度,我们可以用吞吐量和请求延迟来评估应用程序的性能。
- 系统资源的维度,我们可以用 CPU 使用率来评估系统的 CPU 使用情况。
多个性能问题同时存在,要怎么选择?
在性能测试的领域,流传很广的一个说法是“二八原则”,也就是说 80% 的问题都是由 20% 的代码导致的。只要找出这 20% 的位置,你就可以优化 80% 的性能。所以,我想表达的是,并不是所有的性能问题都值得优化。
- 第一,如果发现是系统资源达到了瓶颈,比如 CPU 使用率达到了 100%,那么首先优化的一定是系统资源使用问题。完成系统资源瓶颈的优化后,我们才要考虑其他问题。
- 第二,针对不同类型的指标,首先去优化那些由瓶颈导致的,性能指标变化幅度最大的问题。比如产生瓶颈后,用户 CPU 使用率升高了 10%,而系统 CPU 使用率却升高了 50%,这个时候就应该首先优化系统 CPU 的使用。
好的应用程序是性能优化的最终目的和结果,系统优化总是为应用程序服务的。所以,必须要使用应用程序的指标,来评估性能优化的整体效果。系统资源的使用情况是影响应用程序性能的根源。所以,需要用系统资源的指标,来观察和分析瓶颈的来源。
有多种优化方法时,要如何选择?
性能优化并非没有成本。性能优化通常会带来复杂度的提升,降低程序的可维护性,还可能在优化一个指标时,引发其他指标的异常。也就是说,很可能你优化了一个指标,另一个指标的性能却变差了。
一个很典型的例子是我将在网络部分讲到的 DPDK(Data Plane Development Kit)。DPDK 是一种优化网络处理速度的方法,它通过绕开内核网络协议栈的方法,提升网络的处理能力。不过它有一个很典型的要求,就是要独占一个 CPU 以及一定数量的内存大页,并且总是以 100% 的 CPU 使用率运行。所以,如果你的 CPU 核数很少,就有点得不偿失了。
CPU 优化
如何才能降低 CPU 使用率,提高 CPU 的并行处理能力
应用程序优化
- 编译器优化:很多编译器都会提供优化选项,适当开启它们,在编译阶段你就可以获得编译器的帮助,来提升性能。比如, gcc 就提供了优化选项 -O2,开启后会自动对应用程序的代码进行优化。
- 算法优化:使用复杂度更低的算法,可以显著加快处理速度。比如,在数据比较大的情况下,可以用 O(nlogn) 的排序算法(如快排、归并排序等),代替 O(n^2) 的排序算法(如冒泡、插入排序等)。
- 异步处理:使用异步处理,可以避免程序因为等待某个资源而一直阻塞,从而提升程序的并发处理能力。比如,把轮询替换为事件通知,就可以避免轮询耗费 CPU 的问题。
- 多线程代替多进程:前面讲过,相对于进程的上下文切换,线程的上下文切换并不切换进程地址空间,因此可以降低上下文切换的成本。
- 善用缓存:经常访问的数据或者计算过程中的步骤,可以放到内存中缓存起来,这样在下次用时就能直接从内存中获取,加快程序的处理速度。
系统优化
- CPU 绑定:把进程绑定到一个或者多个 CPU 上,可以提高 CPU 缓存的命中率,减少跨 CPU 调度带来的上下文切换问题。
- CPU 独占:跟 CPU 绑定类似,进一步将 CPU 分组,并通过 CPU 亲和性机制为其分配进程。这样,这些 CPU 就由指定的进程独占,换句话说,不允许其他进程再来使用这些 CPU。
- 优先级调整:使用 nice 调整进程的优先级,正值调低优先级,负值调高优先级。优先级的数值含义前面我们提到过,忘了的话及时复习一下。在这里,适当降低非核心应用的优先级,增高核心应用的优先级,可以确保核心应用得到优先处理。
- 为进程设置资源限制:使用 Linux cgroups 来设置进程的 CPU 使用上限,可以防止由于某个应用自身的问题,而耗尽系统资源。
- NUMA(Non-Uniform Memory Access)优化:支持 NUMA 的处理器会被划分为多个 node,每个 node 都有自己的本地内存空间。NUMA 优化,其实就是让 CPU 尽可能只访问本地内存。
- 中断负载均衡:无论是软中断还是硬中断,它们的中断处理程序都可能会耗费大量的 CPU。开启 irqbalance 服务或者配置 smp_affinity,就可以把中断处理过程自动负载均衡到多个 CPU 上。
千万避免过早优化
“过早优化是万恶之源” ------高德纳
因为,一方面,优化会带来复杂性的提升,降低可维护性;另一方面,需求不是一成不变的。针对当前情况进行的优化,很可能并不适应快速变化的新需求。这样,在新需求出现时,这些复杂的优化,反而可能阻碍新功能的开发。所以,性能优化最好是逐步完善,动态进行,不追求一步到位,而要首先保证能满足当前的性能要求。当发现性能不满足要求或者出现性能瓶颈时,再根据性能评估的结果,选择最重要的性能问题进行优化。
总结
但是记住,一定要忍住“把 CPU 性能优化到极致”的冲动,因为 CPU 并不是唯一的性能因素。在后续的文章中,我还会介绍更多的性能问题,比如内存、网络、I/O 甚至是架构设计的问题。
内存性能篇
基础篇:Linux内存是怎么工作的?
内存映射
物理内存、虚拟内存
虚拟地址空间的内部又被分为内核空间和用户空间
MMU
内存映射的最小单位,也就是页,通常是 4 KB 大小。这样,每一次内存映射,都需要关联 4 KB 或者 4KB 整数倍的内存空间
虚拟内存空间分布
- 只读段,包括代码和常量等
- 数据段,包括全局变量等
- 堆,包括动态分配的内存,从低地址开始向上增长
- 文件映射段,包括动态库、共享内存等,从高地址开始向下增长
- 栈,包括局部变量和函数调用的上下文等
- 栈的大小是固定的,一般是 8 MB
内存分配与回收
malloc() 是 C 标准库提供的内存分配函数,对应到系统调用上,有两种实现方式,即 brk() 和 mmap()。
- 对小块内存(小于 128K),C 标准库使用
brk()来分配,也就是通过移动堆顶的位置来分配内存。这些内存释放后并不会立刻归还系统,而是被缓存起来,这样就可以重复使用。 - 而大块内存(大于 128K),则直接使用内存映射
mmap()来分配,也就是在文件映射段找一块空闲内存分配出去。
两种方式的优缺点:
- brk() 方式的缓存,可以减少缺页异常的发生,提高内存访问效率。不过,由于这些内存没有归还系统,在内存工作繁忙时,频繁的内存分配和释放会造成内存碎片。
- 而 mmap() 方式分配的内存,会在释放时直接归还系统,所以每次 mmap 都会发生缺页异常。在内存工作繁忙时,频繁的内存分配会导致大量的缺页异常,使内核的管理负担增大。这也是 malloc 只对大块内存使用 mmap 的原因。
当这两种调用发生后,其实并没有真正分配内存。这些内存,都只在首次访问时才分配,也就是通过缺页异常进入内核中,再由内核来分配内存。
在发现内存紧张时,系统就会通过一系列机制来回收内存,比如下面这三种方式:
- 回收缓存,比如使用 LRU(Least Recently Used)算法,回收最近使用最少的内存页面;
- 回收不常访问的内存,把不常用的内存通过交换分区直接写到磁盘中;
- 杀死进程,内存紧张时系统还会通过 OOM(Out of Memory),直接杀掉占用大量内存的进程。
第二种方式回收不常访问的内存时,会用到交换分区(以下简称 Swap)。Swap 其实就是把一块磁盘空间当成内存来用。它可以把进程暂时不用的数据存储到磁盘中(这个过程称为换出),当进程访问这些内存时,再从磁盘读取这些数据到内存中(这个过程称为换入)。
第三种方式提到的 OOM(Out of Memory),其实是内核的一种保护机制。它监控进程的内存使用情况,并且使用 oom_score 为每个进程的内存使用情况进行评分:
- 一个进程消耗的内存越大,oom_score 就越大;
- 一个进程运行占用的 CPU 越多,oom_score 就越小。
oom_adj 的范围是 [-17, 15],数值越大,表示进程越容易被 OOM 杀死;数值越小,表示进程越不容易被 OOM 杀死,其中 -17 表示禁止 OOM
$ echo -16 > /proc/$(pidof sshd)/oom_adj如何查看内存使用情况
free:显示整个系统的内存使用情况
$ free
total used free shared buff/cache available
Mem: 16256072 3346112 9158976 553052 3750984 12019400
Swap: 2097148 0 2097148- 第一列,total 是总内存大小
- 第二列,used 是已使用内存的大小,包含了共享内存
- 第三列,free 是未使用内存的大小
- 第四列,shared 是共享内存的大小
- 第五列,buff/cache 是缓存和缓冲区的大小
- 最后一列,available 是新进程可用内存的大小。
available 不仅包含未使用内存,还包括了可回收的缓存,所以一般会比未使用内存更大。不过,并不是所有缓存都可以回收,因为有些缓存可能正在使用中。
top:显示系统进程
$ top
top - 20:07:20 up 1 day, 6:22, 2 users, load average: 1.03, 1.07, 1.08
Tasks: 373 total, 1 running, 287 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.4 us, 0.4 sy, 0.0 ni, 99.1 id, 0.0 wa, 0.0 hi, 0.1 si, 0.0 st
KiB Mem : 16256072 total, 9142632 free, 3357236 used, 3756204 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 12008200 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1409 root 20 0 613756 21488 18468 S 1.3 0.1 29:10.55 sunloginclient
9609 shibin 20 0 554816 99080 58432 S 1.3 0.6 5:40.62 code
9635 shibin 20 0 50.679g 450616 108800 S 1.3 2.8 9:45.91 code
13166 shibin 20 0 645548 32388 25984 S 1.0 0.2 0:00.03 baidu-qimpanel
13097 shibin 20 0 51472 4060 3268 R 0.7 0.0 0:00.29 top
11 root 20 0 0 0 0 I 0.3 0.0 0:53.65 rcu_sched
1112 syslog 20 0 263040 5260 3652 S 0.3 0.0 0:47.91 rsyslogd
1213 root 20 0 67912 6536 6040 S 0.3 0.0 5:41.31 oray_rundaemon
1576 root 20 0 17.309g 45192 6776 S 0.3 0.3 1:47.40 LAgent
2509 gdm 20 0 668824 23868 18664 S 0.3 0.1 0:23.29 gsd-color
5042 shibin 20 0 51392 5844 3836 S 0.3 0.0 0:58.80 dbus-daemon
6358 shibin 20 0 1000684 99524 70460 S 0.3 0.6 3:07.28 Xorg
6464 shibin 20 0 4414516 290964 126284 S 0.3 1.8 6:51.63 gnome-shell
6577 shibin 20 0 594344 23796 18568 S 0.3 0.1 0:30.36 gsd-color
7386 root 20 0 0 0 0 I 0.3 0.0 0:00.17 kworker/10:0-mm
1 root 20 0 225728 9304 6620 S 0.0 0.1 0:22.49 systemd注意两点:
- VIRT 是进程虚拟内存的大小,只要是进程申请过的内存,即便还没有真正分配物理内存,也会计算在内
- RES 是常驻内存的大小,也就是进程实际使用的物理内存大小,但不包括 Swap 和共享内存
- SHR 是共享内存的大小,比如与其他进程共同使用的共享内存、加载的动态链接库以及程序的代码段等
- %MEM 是进程使用物理内存占系统总内存的百分比
第一,虚拟内存通常并不会全部分配物理内存。从上面的输出,你可以发现每个进程的虚拟内存都比常驻内存大得多。
第二,共享内存 SHR 并不一定是共享的,比方说,程序的代码段、非共享的动态链接库,也都算在 SHR 里。当然,SHR 也包括了进程间真正共享的内存。所以在计算多个进程的内存使用时,不要把所有进程的 SHR 直接相加得出结果。
基础篇:怎么理解内存中的Buffer和Cache?
$ free
free
total used free shared buff/cache available
Mem: 16256072 3334656 9162968 552992 3758448 12030916
Swap: 2097148 0 2097148缓存是 Buffer 和 Cache 两部分的总和
free 数据的来源
man free
proc 文件系统
/proc 是 Linux 内核提供的一种特殊文件系统,是用户跟内核交互的接口
Buffers %lu
Relatively temporary storage for raw disk blocks that shouldn't get tremendously large (20MB or so).
Cached %lu
In-memory cache for files read from the disk (the page cache). Doesn't include SwapCached.
...
SReclaimable %lu (since Linux 2.6.19)
Part of Slab, that might be reclaimed, such as caches.
SUnreclaim %lu (since Linux 2.6.19)
Part of Slab, that cannot be reclaimed on memory pressure.- Buffers 是对原始磁盘块的临时存储,也就是用来缓存磁盘的数据,通常不会特别大(20MB 左右)。这样,内核就可以把分散的写集中起来,统一优化磁盘的写入,比如可以把多次小的写合并成单次大的写等等。
- Cached 是从磁盘读取文件的页缓存,也就是用来缓存从文件读取的数据。这样,下次访问这些文件数据时,就可以直接从内存中快速获取,而不需要再次访问缓慢的磁盘。
- SReclaimable 是 Slab 的一部分。Slab 包括两部分,其中的可回收部分,用 SReclaimable 记录;而不可回收部分,用 SUnreclaim 记录
# 清理文件页、目录项、Inodes等各种缓存
$ echo 3 > /proc/sys/vm/drop_caches
# 每隔1秒输出1组数据
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 7743608 1112 92168 0 0 0 0 52 152 0 1 100 0 0
0 0 0 7743608 1112 92168 0 0 0 0 36 92 0 0 100 0 0- Buffer 既可以用作“将要写入磁盘数据的缓存”,也可以用作“从磁盘读取数据的缓存”。
- Cache 既可以用作“从文件读取数据的页缓存”,也可以用作“写文件的页缓存”。
Buffer 是对磁盘数据的缓存,而 Cache 是文件数据的缓存,它们既会用在读请求中,也会用在写请求中
案例篇:如何利用系统缓存优化程序的运行效率?
缓存命中率
指直接通过缓存获取数据的请求次数,占所有数据请求次数的百分比
cachestat 和 cachetop ,它们正是查看系统缓存命中情况的工具。
- cachestat 提供了整个操作系统缓存的读写命中情况。
- cachetop 提供了每个进程的缓存命中情况。
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4052245BD4284CDD
echo "deb https://repo.iovisor.org/apt/xenial xenial main" | sudo tee /etc/apt/sources.list.d/iovisor.list
sudo apt-get update
sudo apt-get install -y bcc-tools libbcc-examples linux-headers-$(uname -r)需要自己配置path
指定文件的缓存大小
pcstat:来查看文件在内存中的缓存大小以及缓存比例。
$ export GOPATH=~/go
$ export PATH=~/go/bin:$PATH
$ go get golang.org/x/sys/unix
$ go get github.com/tobert/pcstat/pcstat案例篇:内存泄漏了,我该如何定位和处理?
内存的分配和回收
bcc 软件包,它提供了一系列的 Linux 性能分析工具,常用来动态追踪进程和内核的行为
memleak(bcc):可以跟踪系统或指定进程的内存分配、释放请求,然后定期输出一个未释放内存和相应调用栈的汇总情况(默认 5 秒)