
内存
可能你已经看过了很多关于内存的文章或是资源,但大多数在回答了两个问题:是什么?怎么用?那问题来了,内存布局结构怎么一点点变成现在这样子的呢(Stack、Heap、Bss、Data、Text)?这篇文章试图用推理来回答这个问题。
第一个程序
时光回到刚刚有汇编的时候,还没有操作系统,也没有ELF格式(程序的存储文件格式),只有一个简单的裸机程序,并且就只有几条的指令。假设如下:
mov ax, 0123H
mov bx, 0456H
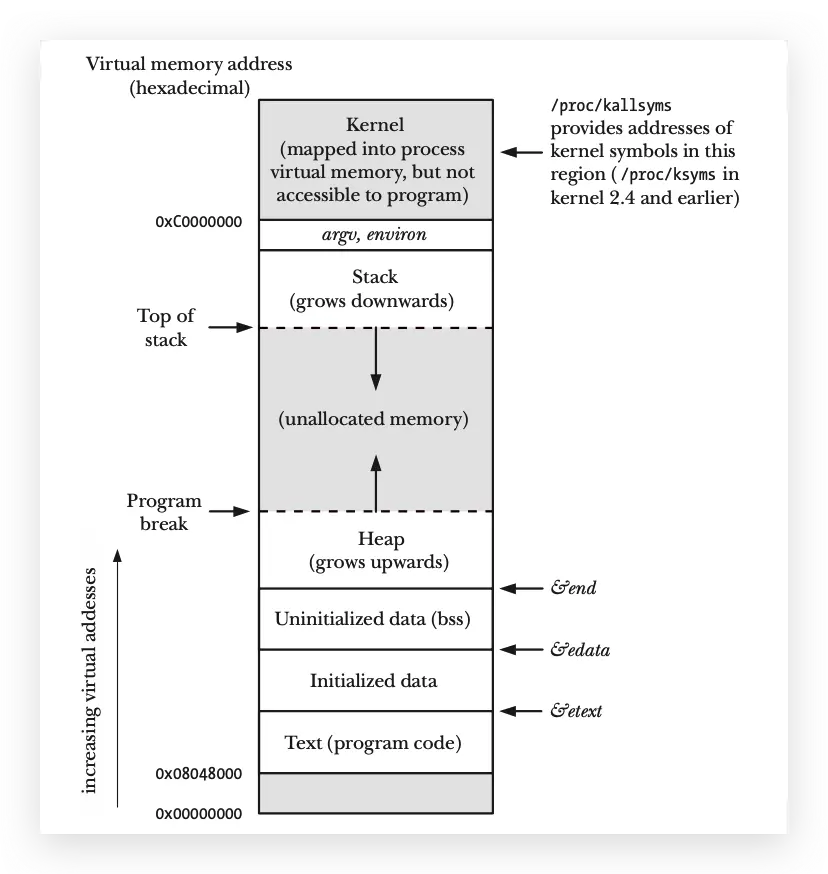
add ax, bx这是一段简单的汇编代码:做加法运算,会被翻译成类似010101 CPU能识别的指令。一条指令会占用特定的字节数。然后,这段程序会被加载到裸机上去运行,在然后,顺序的执行指令上面的1、2、3条指令就结束了。没有内存的栈区,也没有堆区,只有最核心的代码指令部分,很简单,是吧。也就是最初的这点代码,构成了ELF格式中最最最核心的部分-代码段.text。
数据段:所有代码共享
上面这段代码还有些问题,如果我想保存点数据(计算结果),并且让上面代码段中的所有指令都可以去共享,怎么办?新划一块地方专门放这些数据吧。这就有了我们的数据段.data,用来存放的全局变量,这些变量可以被所有代码指令共享;你可能还听过一个叫.bss段,用来存放未初始化的全局变量,这个算优化项,它还有个合适的别名:better save space,对,看名字就知道是用来节省空间的,你都没有初始化的值,我ELF文件也就不用去额外的去保存这部分数据了吧。那为啥全局变量初始化0也会被放到这里呢?你都给0了相当于啥也没给,初始化赋值为0这事,还是交给后面的小伙加载器Loader去做吧,还能腾出来一点空间,毕竟那些年内存、存储可是稀缺资源,又小又金贵。至此,我们有了代码段.text、初始化的数据段.data、未初始化的数据段.bss。
栈区:部分代码块共享
上面程序未必太过于简单了,的确。不过话说回来,整个计算机体系就是构建一层层的抽象和封装上。这时,我们就可以对一些完成了特定功能的代码块指令进行封装,便于复用。问题来了,我这段代码块完成特定功能,但需要提供一些固定大小的内存区域让我去操作并保存数据,怎么办?同样也给你划分一块区域,让你去存放这些数据,需要多少空间你就无脑的循序往后排,用标记记录下位置;当代码块执行完了,你也不用管你刚刚用过的地方,还是用个标记记录回退后的位置就可以了。整个用于这这就是函数执行时,每个函数共享的内存区域 - 函数栈stack,以及函数代码块执行时,每个函数共享数据块的入栈和出栈。
堆:实际使用的时候才知道需要多少内存
程序在运行的过程中,有另一种不确定会使用多少内存的场景:
- 用户输入的内容不知道会有多长
- 读取文件的内容不知道会有多长
- 网络传输的内容不知道会有多长
- ...
所以进程需要一块内存,用来去处理存放这些不确定的内容,这块内存就是堆区heap。堆区的内存是动态分配的,也就是说,你需要多少内存,就给你多少内存,不需要的时候,就还给操作系统。Linux操作系统提供了两个函数 brk 和 mmap去分配内存。由于调用系统的函数是有一定成本的,glibc 对这两个函数进行了封装,提供了 malloc 和 free 函数,用来管理堆区的内存,内部实现就是调用 brk 和 mmap 函数;当需要分配的内存大小小于MMAP_THRESHOLD(默认128k)时,malloc 内部会调用 brk 去调整空间;当大于MMAP_THRESHOLD时,malloc 会去调用 mmap 分配一块匿名的空间去使用;并做了缓存机制,这样做的好处是,减少了系统调用的次数。 另外一个问题,也不确定这些内存块的生命周期是多长,基于这个原因,我们需要一个机制去管理这些内存块,这个机制就是malloc和free,这两个函数就是用来管理堆区的内存块的。最早期的时候,是由程序员来去管理;后来,操作系统也提供了一些机制,比如说:GC,GC就是垃圾回收机制,它会去检测哪些内存块没有被使用了,然后自动释放掉,这样就不用程序员去管理了。
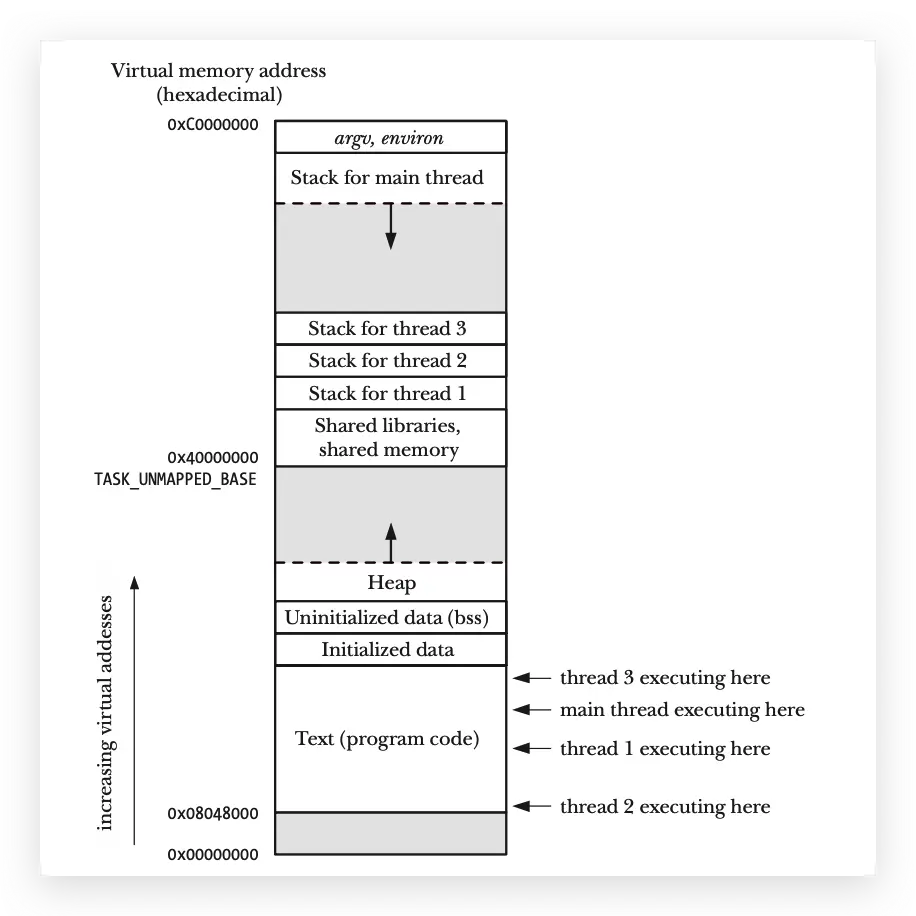
非main线程stack内存
不同的操作系统,线程的实现方式有区别,这里拿 Linux 举例来讲,Linux 的线程是后面加入进去的,意思是说:在 Linux 出现很长一段时间内,是没有线程这个概念,然后看别的操作系统实现了,还挺好用,然后也去实现。可能在学习 Unix/Linux 的过程中,很多部分都会去强调进程通信;但线程出现后,进程通信的这部分被线程替代了:有些用独立进程去做的,现在可以用线程去做了,也会少用到一些进程通信的方式。另外一个原因是,基础的进程通信会过于简单,解决不了一些复杂场景的问题,就会诞生很多框架,对基础的进程通信进行包装,比如 DBus。 回到线程这个话题,如果系统没有线程,那如何去实现?CPU 调度的是进程,在Linux内核代码里面是一个task_struct的结构体。进程创建调用的是 fork 函数,fork 函数内部会调用 clone 函数;而线程的创建pthread_create 函数最终调用的也是 clone 函数,不同于线程创建时,clone 会带很多 Flags 标记(NPTL实现使用的 Flags:CLONE_VM | CLONE_FILES | CLONE_FS | CLONE_SIGHAND | CLONE_THREAD | CLONE_SETTLS | CLONE_PARENT_SETTID | CLONE_CHILD_CLEARTID | CLONE_SYSVSEM),去和当前进程去共享很多资源,内存是通过CLONE_VM去共享的。
线程需要有自己独立的栈空间,这块空间被划到了堆上,会去调用 mmap 分配一块匿名的空间去使用,动态库,线程栈都在这里。如图
在栈上分配内存alloca
alloca 函数是在栈上分配内存,它的实现原理是:在栈上分配一块内存,然后返回这块内存的地址,这块内存的生命周期是和函数的生命周期一样的,函数返回后,这块内存就会被释放掉,省去了内存管理的心智负担。但是,这个函数不是标准 C 语言的函数,而是 GNU C 语言的函数。在 C 语言标准里面,是没有这个函数的,所以,如果你的代码要跨平台,就不要用这个函数了。
全局变量的改进:线程独享
// todo