
Back to "hello world"
以前很喜欢一句,大意是“认知或是成长是盘旋式上升,波浪式前进的”,一个概念多年前是那个意思,但随着时间的推移,阅历的增加,这个概念有了新的含义,你对这个概念的认知也会加深,也有可能有自己独特的理解。比如“垃圾”这个词,当垃圾能回收了,在另外的地方发光发热,有了新的价值,它还是原本那个“垃圾”的意思吗?而这次就回头看看经典的“hello world"。
Hello world
当你新学一门编程语言,写的第一段代码大概就是hello world;又或是当你使用了一个框架,通过框架的Quick start文档,把框架的简单的 Demo跑了起来,这也能被称为广义的hello world ,它更像是一个仪式。下面是 C 语言的版本:
#include <stdio.h>
int main(int argc, char* argv[]) {
printf("hello world\n");
return 0;
}编译运行:
$ cc main.c && ./a.out
hello world预处理
#include <stdio.h>预处理要处理的语句特点
都是#开头,比如:#include、#if、#ifdef、#ifndef、#else、#elif、#define,这个有点类似于,代码用特定标识给预处理器做标记一样;
预处理做了什么?
- 搜索文件
stdio.h;对应有<>和""的搜索规则 - 然后把文件的内容 copy,然后 paste 到当前的文件
- 如果paste 过来的内容里面还有
#include语句,继续上两个步骤
$ cc -E main.c > main_preprocessed.out截取一小段内容:
...
# 1 "main.c"
# 1 "/usr/include/stdio.h" 1 3 4
# 27 "/usr/include/stdio.h" 3 4
# 1 "/usr/include/x86_64-linux-gnu/bits/libc-header-start.h" 1 3 4
# 33 "/usr/include/x86_64-linux-gnu/bits/libc-header-start.h" 3 4
# 1 "/usr/include/features.h" 1 3 4
# 461 "/usr/include/features.h" 3 4
# 1 "/usr/include/x86_64-linux-gnu/sys/cdefs.h" 1 3 4
# 452 "/usr/include/x86_64-linux-gnu/sys/cdefs.h" 3 4
# 1 "/usr/include/x86_64-linux-gnu/bits/wordsize.h" 1 3 4
# 453 "/usr/include/x86_64-linux-gnu/sys/cdefs.h" 2 3 4
# 1 "/usr/include/x86_64-linux-gnu/bits/long-double.h" 1 3 4
# 454 "/usr/include/x86_64-linux-gnu/sys/cdefs.h" 2 3 4
# 462 "/usr/include/features.h" 2 3 4
# 485 "/usr/include/features.h" 3 4
# 1 "/usr/include/x86_64-linux-gnu/gnu/stubs.h" 1 3 4
# 10 "/usr/include/x86_64-linux-gnu/gnu/stubs.h" 3 4
# 1 "/usr/include/x86_64-linux-gnu/gnu/stubs-64.h" 1 3 4
# 11 "/usr/include/x86_64-linux-gnu/gnu/stubs.h" 2 3 4
# 486 "/usr/include/features.h" 2 3 4
# 34 "/usr/include/x86_64-linux-gnu/bits/libc-header-start.h" 2 3 4
# 28 "/usr/include/stdio.h" 2 3 4
...简单翻译:
- 第一行:
main.c的第1行包含了stdio.h文件 - 第三行:
stdio.h文件的第27行包含了libc-header-start.h文件 - 第五行:
libc-header-start.h文件的每33行包含了features.h文件 - 以此类推...
这里有大量的头文件文件检索、读头文件、合并头文件内容到 C 文件;而这只是处理编译一个文件的内容,这里属于有大量重复性的工作,并且这都属于特别慢的 IO 操作,能不能优化?这东西叫precompiled header(PCH),很多编译器和构建系统已经支持了,GCC在3.4版本后就支持了。编译会生成大量中间文件(预处理、编译、汇编)、文件的合并(预处理、链接)、文件编辑(链接),或许花几百块钱升级下硬盘比升级 CPU 的性价比来的更高。
所以预处理到底做了什么?
把一堆东西 copy 过来,里面都是些类型的定义,还有函数的声明。那既然这样,我把原来的代码做一点小的改动,注释#include <stdio.h>
// #include <stdio.h>
int main(int argc, char* argv[]) {
printf("hello world\n");
return 0;
}编译:
Linux上GCC 版本
$ cc --version
cc (Debian 10.2.1-6) 10.2.1 20210110
Copyright (C) 2020 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
$ cc main.c
main.c: In function ‘main’:
main.c:3:5: warning: implicit declaration of function ‘printf’ [-Wimplicit-function-declaration]
3 | printf("hello world\n");
| ^~~~~~
main.c:3:5: warning: incompatible implicit declaration of built-in function ‘printf’
main.c:1:1: note: include ‘<stdio.h>’ or provide a declaration of ‘printf’
+++ |+#include <stdio.h>
1 |macOS上Clang 版本
$ cc --version
Apple clang version 14.0.0 (clang-1400.0.29.202)
Target: x86_64-apple-darwin22.2.0
Thread model: posix
InstalledDir: /Library/Developer/CommandLineTools/usr/bin
$ cc main.c
main.c:6:5: error: implicitly declaring library function 'printf' with type 'int (const char *, ...)' [-Werror,-Wimplicit-function-declaration]
printf("hello world\n");
^
main.c:6:5: note: include the header <stdio.h> or explicitly provide a declaration for 'printf'
1 error generated.不同的编译器处理起来还有点小差异,Clang 直接不让编译通过,GCC择显示警告可以通过;差异在于编译器默认缺省的Werror选项不一样,Clang 的默认配置的更多。那既然前面我们提到#include <stdio.h>只是把一些类型定义和函数声明copy 到了当前的文件,那在改动一点点,自己添加上printf的函数定义,如下
int printf(const char* __restrict, ...);
int main(int argc, char* argv[]) {
printf("hello world\n");
return 0;
}编译运行:
$ cc main.c && ./a.out
hello world可以正常工作了
main 函数是程序的入口
可能你在刚开始学习编程的时候,老师会给你讲 main 函数是程序的入口,尝试用调试器lldb(类似 gdb)跟踪下:
(lldb) thread backtrace
* thread #1, name = 'a.out', stop reason = breakpoint 1.1
* frame #0: 0x000055d2e3f5a144 a.out`main(argc=1, argv=0x00007fffe7a58ee8) at main.c:6:5
frame #1: 0x00007f98049b2d0a libc.so.6`__libc_start_main + 234
frame #2: 0x000055d2e3f5a07a a.out`_start + 42可以看到程序是从_start函数开始的,在调用__libc_start_main函数,最后调用才调用了我们编写的main函数;其中的__libc_start_main是属于 libc 库。
csu/libc-start.c中的代码:
#define LIBC_START_MAIN __libc_start_main
STATIC int LIBC_START_MAIN(
int (*main)(int, char**, char** MAIN_AUXVEC_DECL),
int argc,
char** argv,
__typeof(main) init,
void (*fini)(void),
void (*rtld_fini)(void),
void* stack_end) {
// some code ...
/* Run the program. */
result = main(argc, argv, __environ MAIN_AUXVEC_PARAM);
// some code ...
exit(result);
}main 函数结束意味着程序结束
为啥main函数调用结束,意味着程序的结束?有人可能会给你解释说:main 函数是个特殊的函数;是,它是一个特殊的函数;但问题是: 一个函数的调用结束,为啥能代表程序调用的结束的?return 不能代表着程序的结束;如果你留意看了上面的代码,调用main函数之后,继续调用了一个exit函数,exit函数的作用是退出进程,这才是结束当前进程的原因。
{
result = main(argc, argv, __environ MAIN_AUXVEC_PARAM);
exit(result);
}main 函数的版本
main函数的参数,我见过的大概有下面三个版本,其中最常用的是第二个版本
#include <stdio.h>
// int main(void) {
// int main(int argc, char* argv[]) {
// int main(int argc, char* argv[], char* env[]) {
int main(int argc, char* argv[]) {
printf("hello world\n");
return 0;
}前面的描述已经说明main函数是被其它的函数调用的;那这里还影藏了另一个问题:函数参数对不上既然也能调用?那函数名到底是个什么东西?下面是C 代码对应的 RISC-V 汇编
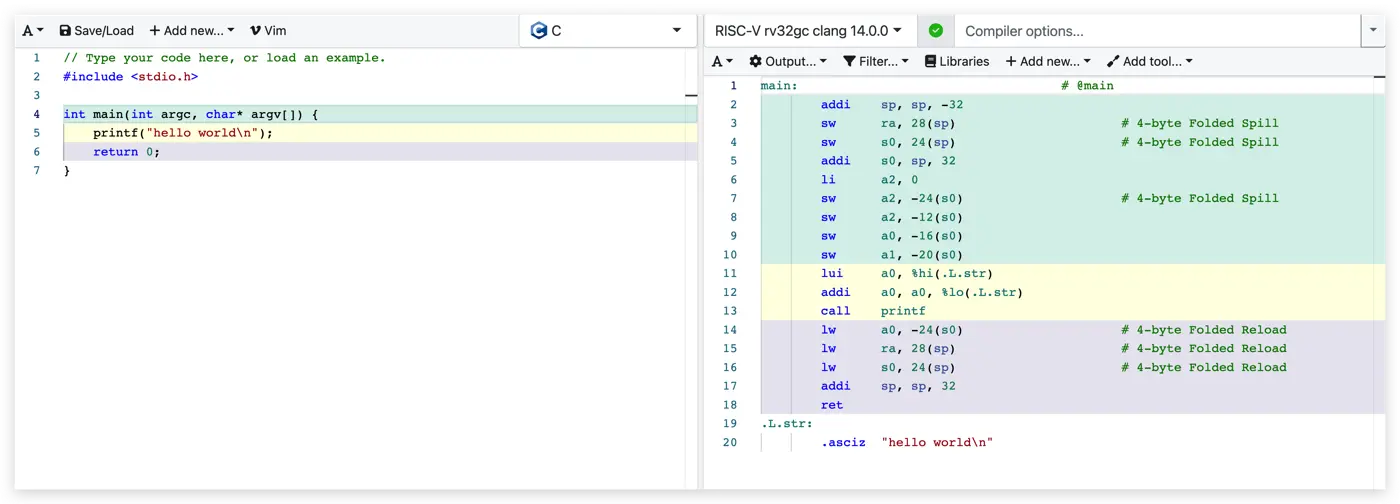
在汇编上能看到的是 main 其实是一个 label,有点类似在 C 语言中写goto语句要转跳的 label,跑偏了;汇编代码最终要通过汇编器转成 CPU要执行的指令,而 CPU 只关心最终要运行的指令,而 label 是不指令的一部分,所以这个 label 其实是给汇编器用的,类似于汇编器在汇编代码中做的标记;
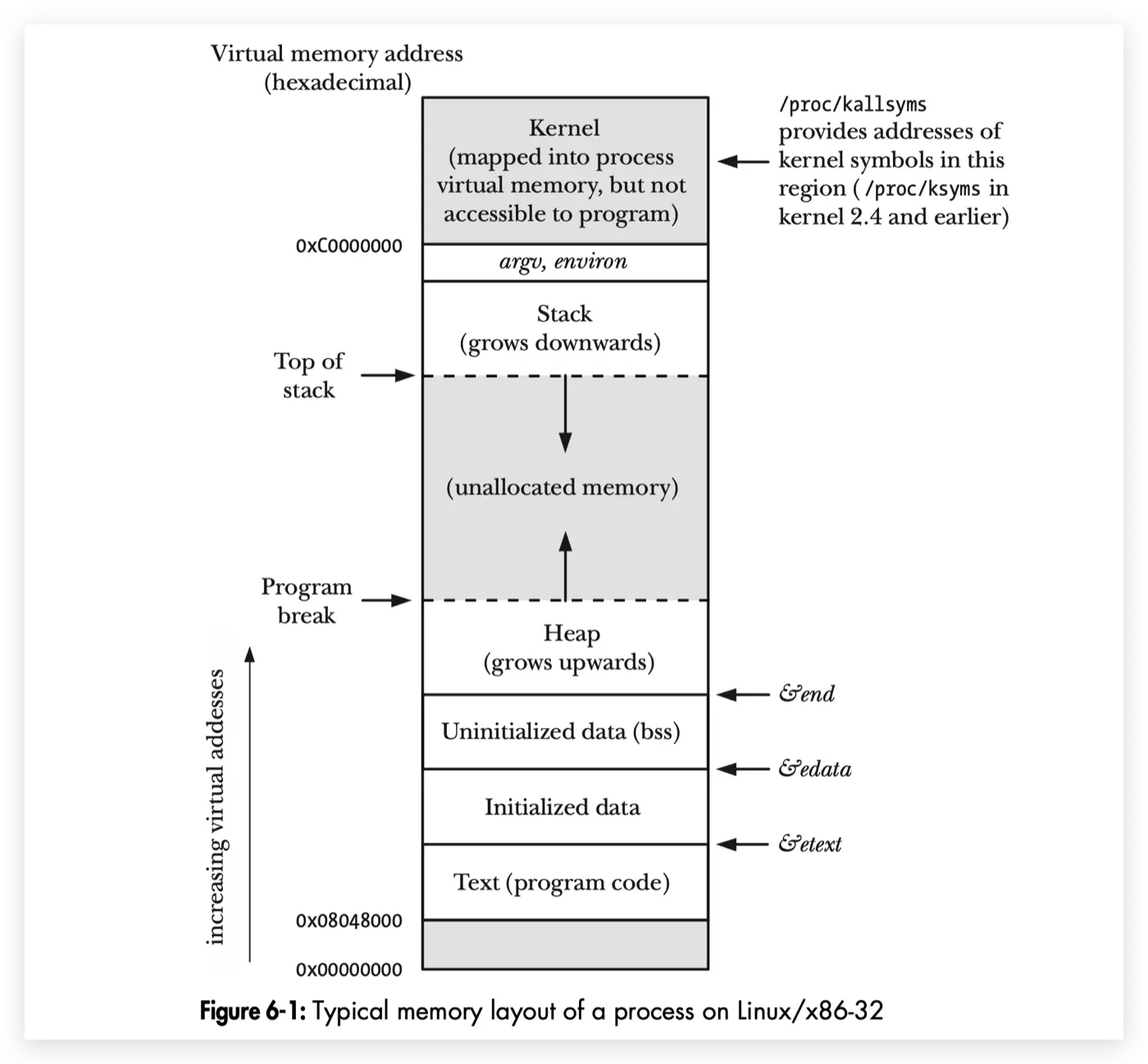
汇编会被翻译成一条条机器指令,而这一条条的指令会被存储到a.out文件中的.text代码段,后面会被loader 加载器加载到内存中去运行,在虚拟内存当中是也是只读的代码段;下面是一个典型的进程的虚拟内存图,机器指令被加载到最底下的 Text 段;
我们现在关心一个问题,这些被翻译后的机器指令在 Text 段中如何存放,以及汇编中的label 被汇编器翻译成什么了?下面是汇编被翻译成机器码的过程图;
依据不同的指令集架构 ISA,不同的指令会有不同的字节大小(看是RISC精简指令集还是CISC复杂指令集,前者是定长的,后者是不定长的;前者也可以不定长,自己加自定义指令),存放时也会依次排放,而函数标签被转换了成标签后面的指令,在 text 代码段中的起始位置,简单的说是一个地址数字,是函数第一条指令的地址数字。前面的main 函数调用追踪已经看到了,函数前面的一串数字0x000055d2e3f5a144之类的
(lldb) thread backtrace
* thread #1, name = 'a.out', stop reason = breakpoint 1.1
* frame #0: 0x000055d2e3f5a144 a.out`main(argc=1, argv=0x00007fffe7a58ee8) at main.c:6:5
frame #1: 0x00007f98049b2d0a libc.so.6`__libc_start_main + 234
frame #2: 0x000055d2e3f5a07a a.out`_start + 42现代的编译器只允许 main 函数有多个版本
其它函数使用
#include <stdio.h>
int foo(int arg) {
printf("foo\n");
}
int main(void) {
foo();
return 0;
}编译:
$ cc main.c
main.c: In function ‘main’:
main.c:7:5: error: too few arguments to function ‘foo’
7 | foo();
| ^~~
main.c:3:5: note: declared here
3 | int foo(int arg) {
| ^~~函数调用的成本
这图是网站 https://godbolt.org/ 的截图,这网站另外一个好的地方在于,用颜色标注了不同的行的 C语言代码会翻译成那些汇编代码,可以看到上面黄色才是正真“工作”的代码,而为了一点“工作”却要执行一堆额外的指令,压栈、记录函数调用完之后的返回的地址、传递函数参数,在“工作”完之后,还有出栈、返回到函数调用完之后的下一条指令。这就是函数调用的成本:为了一些工作指令,要去执行一些额外的“准备工作”指令和“收尾”工作指令。这时个inline关键字https://gcc.gnu.org/onlinedocs/gcc/Inline.html 来了,它会省去函数调用的开销,类似宏的替换一样,把inline函数体的代码替换到代码调用的地方。
printf 函数
#include <stdio.h>
int main(int argc, char* argv[]) {
printf("hello world\n");
printf("hello %s\n", "world");
return 0;
}编译成汇编:
$ cc -S main.c -o main.smain.s代码:
.file "main_ass.c"
.text
.section .rodata
.LC0:
.string "hello world"
.LC1:
.string "world"
.LC2:
.string "hello %s\n"
.text
.globl main
.type main, @function
main:
.LFB6:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl %edi, -4(%rbp)
movq %rsi, -16(%rbp)
leaq .LC0(%rip), %rdi
call puts@PLT
leaq .LC1(%rip), %rsi
leaq .LC2(%rip), %rdi
movl $0, %eax
call printf@PLT
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE6:
.size main, .-main
.ident "GCC: (Debian 10.2.1-6) 10.2.1 20210110"
.section .note.GNU-stack,"",@progbits汇编中能找到两个 call 指令,一个是调用 puts,一个是调用 printf;显然 C 代码中的第一次调用 printf被编译器优化成了 puts;虽然最后的作用效果是一样的,但是,有种“真正执行的函数,不是你所编写的那个函数”的感觉。
main 函数的返回值
新人时常会有个疑问:这个return到底返回给了谁?有什么用?
return 的返回值有什么用?
回答这个问题前需要先回答另一个问题:谁启动了这个程序/进程?实际上大多时候,只有当前进程的父进程才会关心子进程的退出状态,老子关心儿子是怎么挂的,然后根据相关的退出状态做出相应的响应。Linux 里面创建进程的方式:fork + exec函数族 组合方式,这两个函数的调用可能是写在代码里面,也可能是通过 Shell 的交互命令;实际上当你在 Shell 中敲了类似./a.out 这样的程序启动命令,就是去调用fork + exec,然后调用wait函数等待子进程运行结束。简单如下
#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
int main(int argc, char* argv[]) {
if (fork() == 0) {
// child process
char* const argv[] = {"/com.docker.devenvironments.code/hello_world/a.out", NULL};
execvp("/com.docker.devenvironments.code/hello_world/a.out", argv);
} else {
// parent process
int child_exit_status = 0;
wait(&child_exit_status); // wait for child process
printf("child_return_value: %d\n", child_return_value);
}
return 0;
}所以 结合下前面的代码(下面),总结下就是:return 的值是用来退出当前进程的,而一般情况下父进程会关注子进程的退出状态,父进程可以根据这个状态去做相应的响应动作:知道子进程是否是正常结束,正常结束代表工作顺利完成;如果是不正常的退出,会去检查是什么原因导致的,可以做相应的补救措施。
// some code ...
{
result = main(argc, argv, __environ MAIN_AUXVEC_PARAM);
exit(result);
}EXIT_FAILURE和EXIT_SUCCESS
在 stdlib.h 文件中还定义了两个宏常用的宏
// stdlib.h
/* We define these the same for all machines.
Changes from this to the outside world should be done in `_exit'. */
#define EXIT_FAILURE 1 /* Failing exit status. */
#define EXIT_SUCCESS 0 /* Successful exit status. */
// main.c
#include <stdio.h>
int main(int argc, char* argv[]) {
printf("hello world\n");
return EXIT_SUCCESS;
}$?获取进程退出状态
#include <stdio.h>
int main(int argc, char* argv[]) {
printf("hello world\n");
return EXIT_FAILURE;
}编译运行:
$ cc main_exit.c && ./a.out
hello world
$ echo $?
1返回值类型 Int
int 在我电脑上是4个字节,那我改成256
#include <stdio.h>
int main(int argc, char* argv[]) {
printf("hello world\n");
return 256;
}编译运行:
$ cc main.c && ./a.out
hello world
$ echo $?
0把 return 改成257呢,
#include <stdio.h>
int main(int argc, char* argv[]) {
printf("hello world\n");
return 257;
}编译运行:
$ cc main.c && ./a.out
hello world
$ echo $?
1变成了1,这就有意思了;不卖关子,程序的退出方式有很多种,一个 int 用不同的 bit分成了多种情况去使用,如下图,正常退出值的范围是:0~255。所以,return的值是
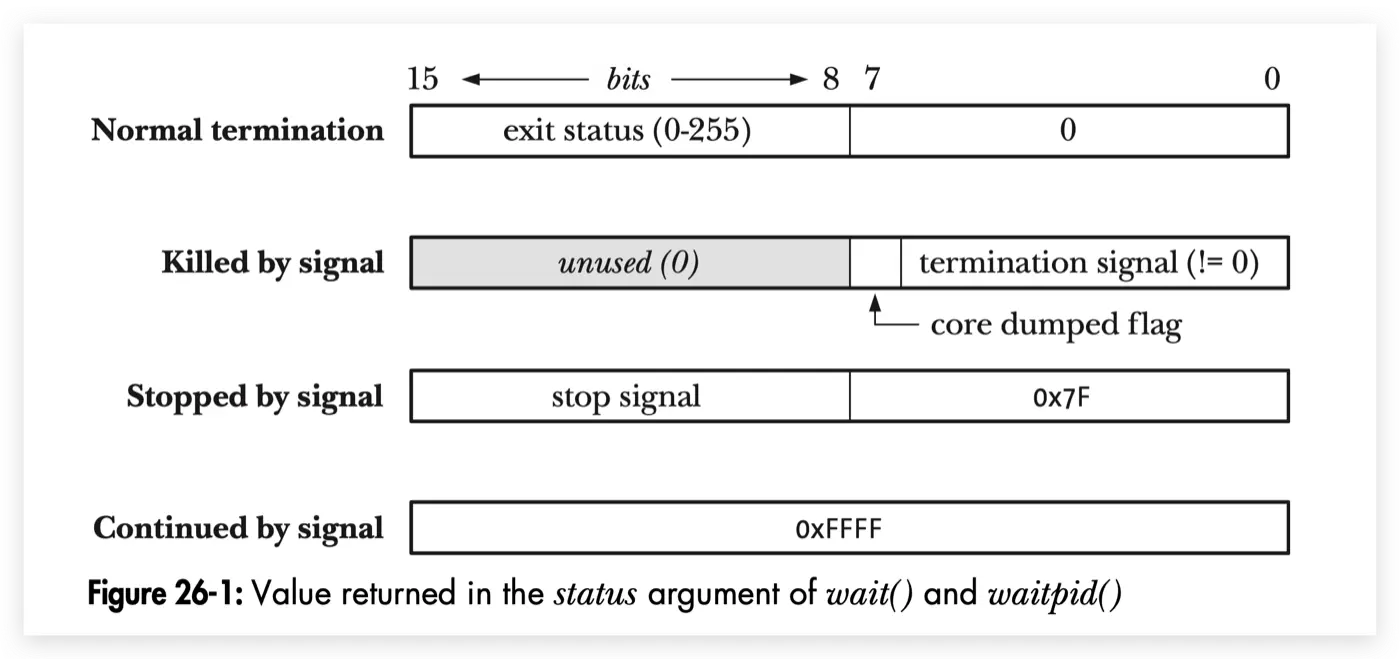
WEXITSTATUS宏可以去获取进程正常退出的状态,也就是子进程正常退出 return返回的值
#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
int main(int argc, char* argv[]) {
if (fork() == 0) {
// child process
char* const argv[] = {"/com.docker.devenvironments.code/hello_world/a.out", NULL};
execvp("/com.docker.devenvironments.code/hello_world/a.out", argv);
} else {
// parent process
int child_exit_status = 0;
int child_normal_termination_exit_status = 0;
wait(&child_exit_status); // wait for child process
child_normal_termination_exit_status = WEXITSTATUS(child_exit_status); // get normal termination exit status
printf("child_return_value: %d\n", child_normal_termination_exit_status);
}
return 0;
}编译运行:
$ cc main.c -o parent.out && ./parent.out
child_return_value: 1这样就能获取到进程最后正常退出的状态;而WEXITSTATUS宏就是做下位移和与运算:
#define WEXITSTATUS(x) ((_W_INT(x) >> 8) & 0x000000ff)